Object detection with synthetic training data
21.03.2023

Machine Learning (ML) algorithms typically require large amounts of data to train for object detection. For example, if we wanted to train a computer vision model to detect cars, we’d need to ensure the training data contains images of a large range of different models of car, in different lighting conditions, landscapes, and weather conditions.
In the case of Supervised Learning, the data must be annotated with the correct ground truth labels to provide the necessary feedback during training for the algorithm to improve. The annotation process is incredibly time-consuming and requires extensive resourcing to complete.
At Rowden, we have used 3D modelling engines to generate synthetic training datasets for drone detection in edge environments, allowing us to easily generate the variation in data required to train a robust model, and enabling us to annotate images automatically. Once the model is optimised to the GPU’s architecture, we can demonstrate the utility of synthetic data for deployed MLOps.
Using synthetic data
Increasingly, Machine Learning engineers are using 3D modelling engines to generate synthetic training datasets. For example, the open-source procedural pipeline Blenderproc harnesses Blender’s modelling and rendering engine to rapidly generate training data annotated with the correct ground truth labels. It does this by using a Ray Tracing algorithm to identify which pixels represent the target object to calculate a corresponding image mask or bounding box.

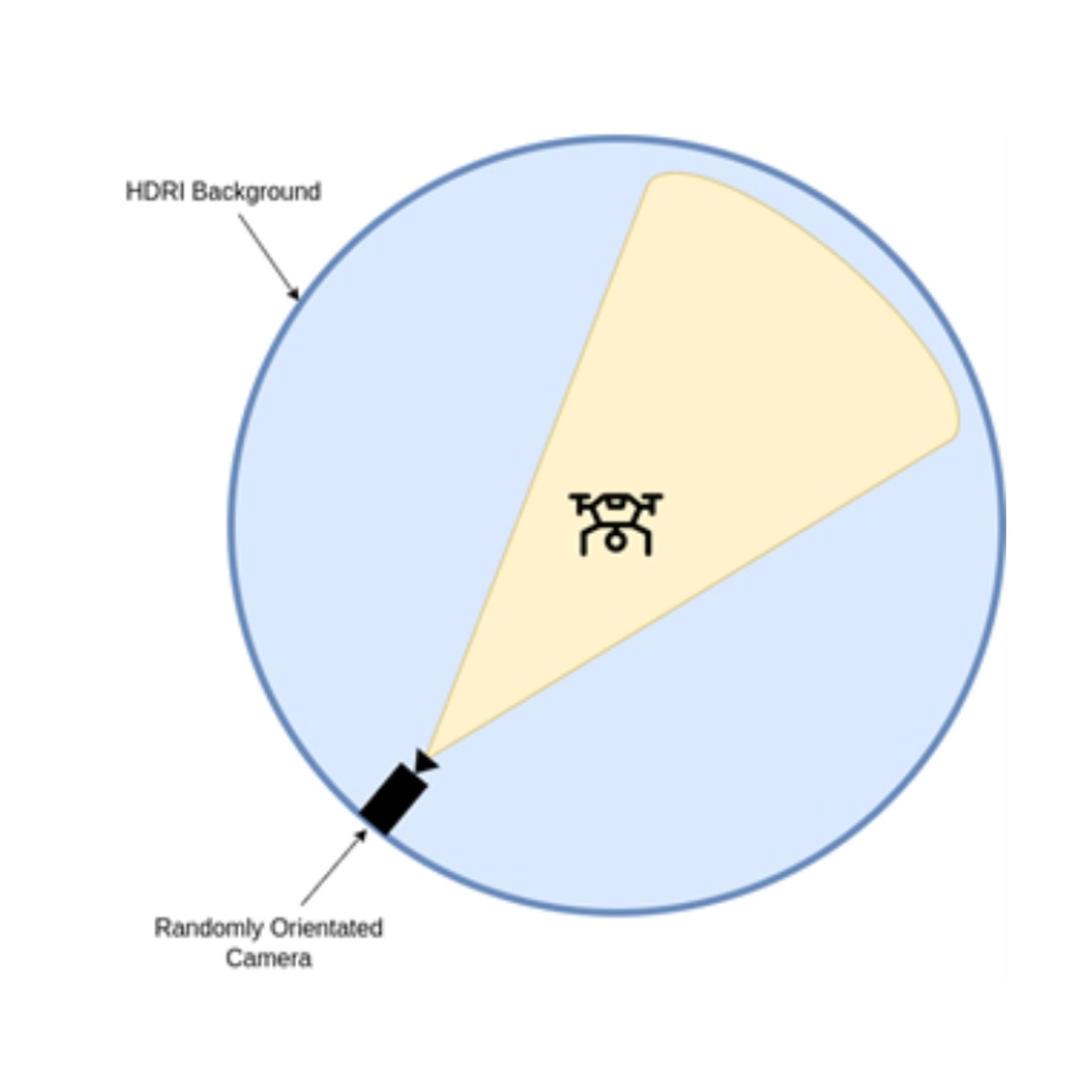
To create a full training set, you need to repeatedly vary the position of the drone in a range of different environments and lighting conditions. This can be done using High Dynamic Range Images (HDRIs); HDRIs can be thought of as a 360 degree panoramic picture that covers all possible angles from a single position, whilst also capturing information about the lighting of the scene. Conveniently, there are a large range of HDRIs available for free online. Here is an example from polyhaven.com:

In Blender, we can use a HDRI to act as the backdrop and lighting for our scene. The process of generating training data is now relatively simple: randomly select a HDRI background and then randomly choose a camera position and angle to render the model of the drone from:
Blenderproc provides a Python library that allows us to easily script this process, whilst also automating the process of annotating the rendered image. For this example, we generated 5k training images using 10 different backgrounds in approximately 1 hour on a NVIDIA RTX 3090 GPU. Here’s a sample of the generated data:
Blenderproc provides a Python library that allows us to easily script this process, whilst also automating the process of annotating the rendered image. For this example, we generated 5k training images using 10 different backgrounds in approximately 1 hour on a NVIDIA RTX 3090 GPU. Here’s a sample of the generated data:

Now that we have an annotated dataset, we can train a model against it.
By far the most common approach when training a model is to perform what is called “transfer learning”, a process that takes a pre-trained existing model and fine tunes it using a different dataset.
For this example, the Rowden ML team took an object detection model architecture called YOLOv5 that had been pre-trained against the COCO dataset to identify and locate 80 different classes of everyday objects such as vehicles and animals. During transfer learning, we freeze the majority of the model and only allow the model to adjust the weights of the final layers of the network in order to tune the model to our drone dataset.
The idea here is that although we are applying the model to a different dataset, the majority of what the layers have learnt to identify will still be relevant (e.g. edge detection, identifying primitive shapes, etc.).
We were able to fine tune the pre-trained YOLOv5 model with good accuracy in 10 minutes using a NVIDIA 3090 RTX GPU. This model could be further improved with more time and data. Here’s a sample of its predictions made against the sample of data shown above:

Real-time deployment at the edge
ML algorithms, and Neural Networks in particular, require large amounts of computational power to run, and it’s only in recent years that edge devices such as phones have been able to run the models locally, rather than transferring the data back to a centralised server.
NVIDIA’s Jetson series of hardware specifically targets ML edge use cases, providing a small form factor standalone device with an NVIDIA GPU. For this example, our team used the smallest of the Jetson devices, the Jetson Nano, but would typically target higher performing platforms such as the NVIDIA AGX for production environments.
NVIDIA provide a SDK called DeepStream that optimises the use of the on-board GPU for both video decoding and model inference, allowing a Jetson device to annotate multiple video streams simultaneously by feeding them through a Deep Neural Network in real-time. With everything happening locally on the device, a model can be deployed in internet-denied environments or scenarios that require fast responses to the model’s predictions.
To make the most of the onboard GPU’s processing power, we must first compile our trained model into a binary format that has been optimised to the GPU’s particular architecture. For this example, we exported the model to the .engine file format and configured the DeepStream pipeline to use it.
Here is how the model performed on a real video feed after being trained on the synthetic dataset:
Whilst there are a few false positives, this is an impressive performance for a model that has only been trained on synthetic data of a generic drone, and could easily be improved by generating a larger range of different drone images (and examples with no drones present).
Conclusion
With the current pace of development in Virtual and Augmented Reality, synthetic datasets and virtual environments will play an increasingly prominent role in Artificial Intelligence and Machine Learning.
Importantly, these approaches will help to accelerate the operationalisation of ML for users at the edge.


contact us
ROWDEN TECHNOLOGIES 2024©